투자를 결정하기 위해 어떤 것들을 고려해야 하나 고민하다가 문득 궁금해 졌습니다.
과연 특정 기업의 주가와 뉴스는 어떤 관계가 있을까?
긍정적인 뉴스가 많으면 주가가 올라갈까?
부정적인 뉴스가 많으면 주가는 내려가나?
이런 점들을 간편하게 알아낼 수 있는 방법이 없을까? 이렇게 고민하다가 구글 검색을 통해 어떤 문장이 긍정적인지, 부정적인지를 알아내는 방법이 있다는 것을 보았습니다.
먼저 결과부터 보여드리면 일정한 기간동안 테슬라 뉴스를 검색하여 긍정/중립/부정적인 뉴스의 개수를 그래프로 그려보고, 그것과 비교할 수 있도록 그 기간동안의 주가 등락률을 그래프로 표시해보았습니다.
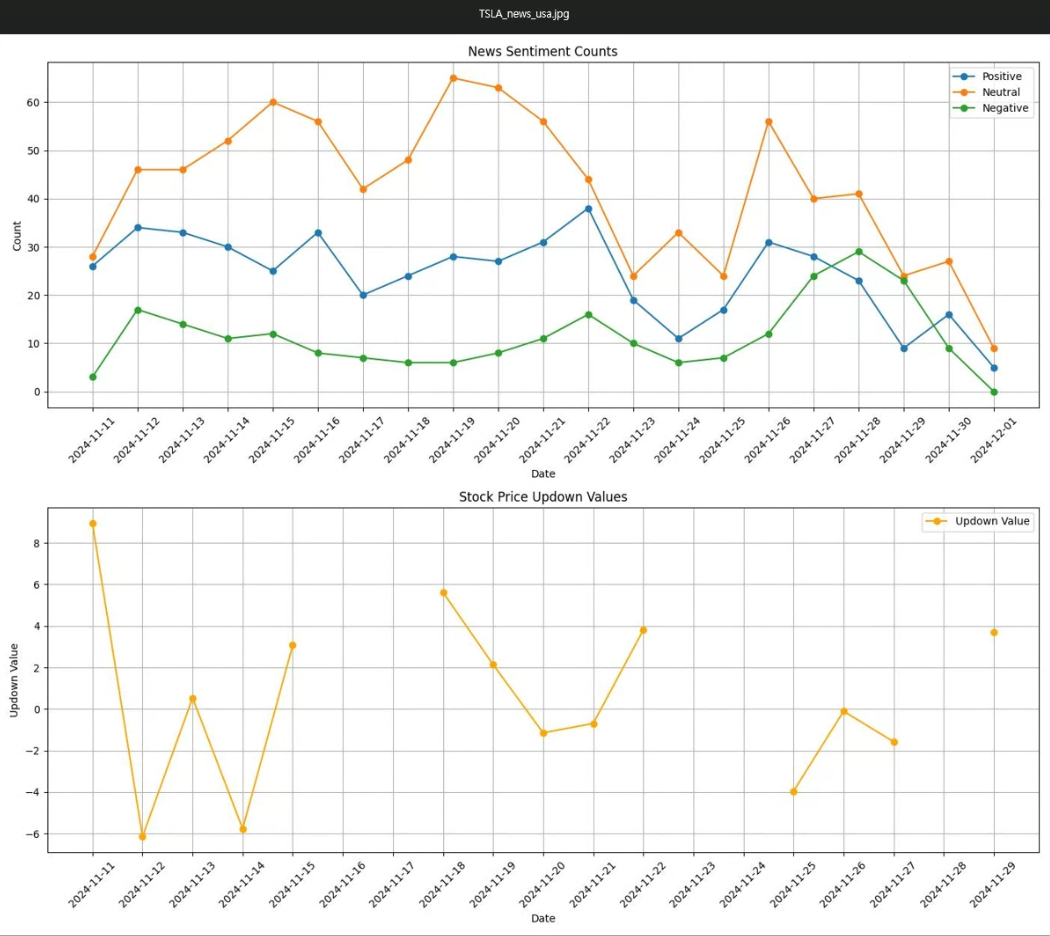
그래프 색을 좀 손봐야겠네요. 그래도 재미로 한번 봐주세요. 뉴스와 주가의 등락이 관련이 있어 보이나요? ^^
1. NewsApiClient
일단은 내가 관심있는 주식들은 미국주식들이니 미국뉴스들을 검색하는 방법이 필요했다.
NewsApiClient는 뉴스 기사를 검색하고 가져오는 데 사용되는 API 클라이언트입니다. 사용자는 API 키를 통해 인증을 받고, HTTP 요청을 통해 데이터를 주고받습니다. API키를 받는 방법은 다른 분들이 작성해 놓은 부분이 있으니 저는 언급하지 않겠습니다.
from newsapi import NewsApiClient
# News API 클라이언트 초기화
newsapi = NewsApiClient(api_key='받은키넣는곳')
news_title = 'Apple'
from_date = '2024-12-01T00:00:00'
to_date = '2024-12-02T00:00:00'
all_articles = newsapi.get_everything(q=news_title, language='en', sort_by='relevancy', from_param=from_date, to=to_date)
for article in all_articles['articles']:
title = article['title']
print(title)위와 같은 코드로 설정한 기간의 Apple 로 검색되는 News 제목들이 표시되는 것을 확인할 수 있습니다.
2. 감정분석
글의 내용이 긍정적인지 부정적인지를 판단할 수 있는 라이브러리가 있는데 이름이 TextBlob입니다. 검색한 설명에는 자연어 처리(NLP)작업을 간단하게 수행할 수 있도록 도와준다고 합니다.
한글보다는 영어인 경우에 동작하는 것 같습니다. 한글은 테스트 해봤는데 잘 안되는거 같아요.
from textblob import TextBlob
for article in all_articles['articles']:
title = article['title']
analysis = TextBlob(title)
sentiment = round(analysis.sentiment.polarity, 3) # 소수점 셋째 자리까지 반올림
print(f"Title: {title}\nSentiment: {sentiment}\n"1번에서의 코드에 이어 위와 같이 print 해보면 뉴스 타이틀과 그 뉴스에 대한 감정 지수가 출력됩니다.
숫자로 나오는데 양수이면 긍정적인 뉴스, 음수이면 부정적인 뉴스이다. 0.0 이라면 중립입니다.
3. 번역
위와 같이 했더니 영어로 뉴스제목과 숫자가 나왔는데, 영어가 많이 안되다보니 이게 긍정적이라고 나오는데 맞는건지 확인하기가 힘듭니다. 그래서 번역을 해서 출력해보기로 했습니다. 검색하여 젤 만만한 GoogleTranslator를 사용하기로 하였습니다. 다음과 같은 코드를 통해 번역된 뉴스제목과 감정지수를 확인할 수 있습니다.
from deep_translator import GoogleTranslator
# 번역기 초기화
translator = GoogleTranslator(source='en', target='ko')
for article in all_articles['articles']:
title = article['title']
translated_title = translator.translate(title)
analysis = TextBlob(title)
sentiment = round(analysis.sentiment.polarity, 3) # 소수점 셋째 자리까지 반올림
print(f"Translated Title: {translated_title}\nSentiment: {sentiment}\n")

엔비디아 뉴스를 검색하여 출력했더니 위와 같이 번역이 되었습니다. 얼추 맞는거 같은 느낌이 들기도 합니다.
4. 주가등락률
다음과 같이 야후파이넨스를 통해 미국 주식의 종가를 얻어오고, 그 종가를 이용하여 바로 전날의 주가와 계산하여 등락률을 출력할 수 있습니다.
import yfinance as yf
symbol = "NVDA"
delta_value = -1 #하루전의 의미
# 미국 동부 시간대 설정
est = pytz.timezone('America/New_York')
today = datetime.now(est)
yesterday = today - timedelta(days=abs(delta_value))
yesterday_str = yesterday.strftime('%Y-%m-%d')
data = yf.download(symbol, period='3mo', interval='1d')
if not data.empty and yesterday_str in data.index:
# 등락률 계산
data['Percentage Change'] = data['Close'].pct_change() * 100
# 특정 날짜의 등락률 가져오기
change_rate = data['Percentage Change'].loc[yesterday_str] # loc를 사용하여 날짜로 접근
print(f"Updown {yesterday_str}: {change_rate:.2f}%")
else:
print(f"{yesterday_str}에 대한 데이터가 없습니다.")
5. 그래프 그리기
아래와 같은 코드로 그래프를 그릴 수 있는데요. 1번 그래프에서 positive_counts, neutral_counts, negative_counts 에 뉴스 감정결과가 들어있고, 아래쪽 그래프의 updown_values 에 주가 등락률 정보들을 넣으면 처음 보여드렸던 두개의 그래프를 볼 수 있습니다.
import matplotlib.pyplot as plt
# 그래프 그리기
plt.figure(figsize=(14, 12))
# 1. 뉴스 감정 카운트 그래프
plt.subplot(2, 1, 1)
plt.plot(dates, positive_counts, label='Positive', marker='o')
plt.plot(dates, neutral_counts, label='Neutral', marker='o')
plt.plot(dates, negative_counts, label='Negative', marker='o')
plt.xlabel('Date')
plt.ylabel('Count')
plt.title('News Sentiment Counts')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
# 2. 주가 등락률 그래프
plt.subplot(2, 1, 2)
plt.plot(dates, updown_values, label='Updown Value', color='orange', marker='o')
plt.xlabel('Date')
plt.ylabel('Updown Value')
plt.title('Stock Price Updown Values')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
plt.tight_layout()
plt.savefig(f'D:\\{param}_news_usa.jpg', format='jpg')
6. 전체코드
import sys
import pandas as pd
from newsapi import NewsApiClient
from textblob import TextBlob
from deep_translator import GoogleTranslator
from fpdf import FPDF
from datetime import datetime, timedelta, time as dt_time # datetime.time을 dt_time으로 import
import requests
import time # time 모듈을 import
import pytz # pytz 모듈을 import
import yfinance as yf
import matplotlib.pyplot as plt
# 명령행 인수 확인
if len(sys.argv) < 2:
print("사용법: python script.py <파라미터>")
sys.exit(1)
# 첫 번째 인수를 파라미터로 사용
param = sys.argv[1]
param2 = sys.argv[2]
# News API 클라이언트 초기화
newsapi = NewsApiClient(api_key='키받아서넣는곳')
# 번역기 초기화
translator = GoogleTranslator(source='en', target='ko')
# 미국 동부 시간대 설정
est = pytz.timezone('America/New_York')
utc = pytz.utc
def GetNewsData(news_title, from_date, to_date):
# 특정 주식에 대한 뉴스 검색
all_articles = newsapi.get_everything(q=news_title, language='en', sort_by='relevancy', from_param=from_date, to=to_date)
# 데이터를 저장할 리스트 초기화
data = []
# 뉴스 제목과 감정 분석 결과 출력 및 번역
for article in all_articles['articles']:
title = article['title']
published_at = article['publishedAt'] # 뉴스 게시 시간
source = article['source']['name'] # 뉴스 출처 추가
if title != "[Removed]":
analysis = TextBlob(title)
sentiment = round(analysis.sentiment.polarity, 3) # 소수점 셋째 자리까지 반올림
translated_title = translator.translate(title)
data.append([translated_title, sentiment, published_at, source])
#print(f"Translated Title: {translated_title}\nSentiment: {sentiment}\nPublished At: {published_at}\n\nSource: {source}\n")
# 데이터프레임 생성
df = pd.DataFrame(data, columns=['Translated Title', 'Sentiment', 'Published At', 'Source'])
return df
def GetNewsCount(news_title, from_date, to_date):
print(f"{from_date} ~ {to_date} Find News => {news_title}")
dataframe = GetNewsData(news_title, from_date, to_date)
# 데이터 통계 출력
total_data_count = len(dataframe)
positive_sentiment_count = len(dataframe[dataframe['Sentiment'] > 0])
neutral_sentiment_count = len(dataframe[dataframe['Sentiment'] == 0])
negative_sentiment_count = len(dataframe[dataframe['Sentiment'] < 0])
return positive_sentiment_count, neutral_sentiment_count, negative_sentiment_count
def get_stock_company(ticker_symbol):
# Ticker 객체 생성
ticker = yf.Ticker(ticker_symbol)
# Ticker의 정보 가져오기
info = ticker.info
return info.get('shortName', None)
def get_enddate_morning_str(delta_value):
today = datetime.now(est)
today_date = today.strftime('%Y-%m-%dT%H:%M:%S')
# 어제 날짜 오전
yesterday = today - timedelta(days=abs(delta_value))
yesterday = yesterday.replace(hour=9, minute=30, second=0, microsecond=0)
yesterday_date = yesterday.strftime('%Y-%m-%dT%H:%M:%S')
return yesterday_date
def get_startdate_evening_str(delta_value):
today = datetime.now(est)
today_date = today.strftime('%Y-%m-%dT%H:%M:%S')
beforeyesterday = today - timedelta(days=abs(delta_value))
beforeyesterday = beforeyesterday.replace(hour=16, minute=0, second=0, microsecond=0)
beforeyesterday_date = beforeyesterday.strftime('%Y-%m-%dT%H:%M:%S')
return beforeyesterday_date
# 데이터 저장을 위한 리스트 초기화
dates = []
positive_counts = []
neutral_counts = []
negative_counts = []
updown_values = []
def get_newscount_priceupdown(delta_value):
# 어제 날짜 오전
yesterday_date = get_enddate_morning_str(delta_value)
# 그제 날짜 오후
beforeyesterday_date = get_startdate_evening_str(delta_value-1)
company_name = get_stock_company(param)
#Execute_get_news_report(param, yesterday_date, today_date)
positive_value, neutral_value, negative_value = GetNewsCount(param2, beforeyesterday_date, yesterday_date)
date_str, updown_value = get_stock_price_updown(param, delta_value)
# 데이터 저장
dates.append(date_str)
positive_counts.append(positive_value)
neutral_counts.append(neutral_value)
negative_counts.append(negative_value)
updown_values.append(updown_value)
for number in range(21, 0, -1): # range(1, 11)은 1부터 10까지의 숫자를 생성
delta_value = number * -1
get_newscount_priceupdown(delta_value)
# 그래프 그리기
plt.figure(figsize=(14, 12))
# 1. 뉴스 감정 카운트 그래프
plt.subplot(2, 1, 1)
plt.plot(dates, positive_counts, label='Positive', marker='o')
plt.plot(dates, neutral_counts, label='Neutral', marker='o')
plt.plot(dates, negative_counts, label='Negative', marker='o')
plt.xlabel('Date')
plt.ylabel('Count')
plt.title('News Sentiment Counts')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
# 2. 주가 등락률 그래프
plt.subplot(2, 1, 2)
plt.plot(dates, updown_values, label='Updown Value', color='orange', marker='o')
plt.xlabel('Date')
plt.ylabel('Updown Value')
plt.title('Stock Price Updown Values')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
plt.tight_layout()
plt.savefig(f'D:\\{param}_news_usa.jpg', format='jpg')
위의 코드를 test.py로 저장했다고 하면 실행할때 다음과 같이 실행한다면 첫번째 param으로 주가정보를 얻고, 두번째 param으로 뉴스정보를 얻게 됩니다.
test.py TSLA Tesla
7. 마치며
흥미로 위와 같은 작업을 해봤는데, 실제로 긴 기간동안의 데이터를 얻을 수 있는지는 아직 잘 모르겠습니다.
재미로 봐주세요 ㅎㅎ 감사합니다.
'투자' 카테고리의 다른 글
| Intel 에 대한 2025년 투자 의견 (0) | 2025.02.28 |
|---|---|
| 파이코인의 2025년 전망 (1) | 2025.02.25 |
| 5. 투자를 결정할 지표들 (금리:base interest rate) (7) | 2023.09.05 |
| 3. 투자를 결정할 지표들 (실업률:Unemployment Rate) (0) | 2023.08.31 |
| 2. 투자를 결정할 지표들 (소비자물가지수:CPI) (2) | 2023.08.30 |



